

February 2022 – Volume 25, Number 4
Javad Behesht Aeen
Department of Foreign Languages, Shiraz Branch
Islamic Azad University, Shiraz, Iran
<javad.beheshtaeen![]() gmail.com>
gmail.com>
Ehsan Rassaei (Corresponding Author)
Department of Foreign Languages, Shiraz Branch
Majan University College, Muscat, Oman
Islamic Azad University, Shiraz, Iran
<ehsanrassaei![]() yahoo.com>
yahoo.com>
Mohammad Javad Riasati
Department of Foreign Languages, Shiraz Branch
Islamic Azad University, Shiraz, Iran
<Mjriasati2002![]() yahoo.com>
yahoo.com>
Mostafa Zamanian
Department of Foreign Languages, Shiraz Branch
Islamic Azad University, Shiraz, Iran
<mustafazamanian![]() yahoo.com>
yahoo.com>
Abstract
Taking into account the facilitative role of mobile-mediated communication for promoting EFL learners’ L2 development, this study investigated Iranian EFL learners’ perceptions of recast and their modified output through face-to-face, audio, and video-based mobile-mediated communication. To this end, sixty intermediate EFL learners at two different language institutes were selected. They were randomly assigned into three groups namely, face-to-face, audio- and video-based conditions. During mobile-mediated interactions in three sessions, the participants received recasts for their errors, and then listened to the recorded episodes of their incorrect utterances followed by interlocutors’ feedback via stimulated recall interviews. Afterwards, learners’ stimulated recall interviews were collected in relation to learners’ perceptions of recasts they received. The results of Chi-Square analysis revealed that the audio-based group had more accurate perceptions of recasts provided to them compared to the other two groups. Moreover, the analysis of learners’ modified output indicated no statistical significance among the three groups. The study concluded that mobile-delivered recasts can be considered as noticeable to EFL learners as the conventional face-to-face ones.
Keywords: corrective feedback, mobile-mediated language learning, modified output, recast, pandemic
Concerning the Uptake of Corrective Feedback
There is a rich body of literature over the past three decades that shows the benefits of corrective feedback (CF) for the second language (L2) development (e.g., Lyster & Saito, 2010; Nassaji, 2009; Lyster & Ranta, 1997; Sheen, 2010; Boston, 2021; Desouky, 2020; Kourtali & Révész, 2020). A recast which is defined as a “teacher’s reformulation of all or part of a student’s utterance, minus the error” (Lyster & Ranta, 1997, p.46) is among the most frequently used types of CF in some instructional settings (Lyster & Ranta, 1997; Sheen, 2004). Although a number of previous studies of recasts have focused on traditional face-to-face classrooms (e.g., Lyster & Saito, 2010; Nassaji, 2009), researchers are now turning their attention to other aspects of providing recasts to learners, especially in technology-based platforms (e.g., Rassaei, 2019; Sachs & Suh, 2007; Shintani, 2016; Yilmaz, 2012; Yilmaz & Yuksel, 2011). Modified output defined as learners’ attempts to modify problematic utterances following corrective feedback has been the focus of research by a number of studies. Researchers have been arguing about the level of awareness needed to facilitate modified output. According to Swain (2006), a high level of awareness and cognitive effort is needed in order for learners to use the reformulated form when they are given feedback whether their effort leads to a target-like modified output or a non-target-like one. A number of researchers (e.g., Long, 1996; Mackey, 2006; Rassaei, 2019) have suggested that simply noticing the corrective function of recasts is not a sufficient condition for the successful reformulation of the problematic part by language learners. Rather, it requires ‘understanding’ in the sense introduced by Schmidt (1990) which asserts that L2 learners sometimes are not able to make a logical connection between what is said and what is meant. In situations like these, corrective feedback can play a pivotal role. “Corrective feedback provides a potential solution to this problem since it juxtaposes the learner’s form i with a target language form i+I and the learner is put in an ideal position to notice the gap” (Schmidt, 1990, p. 313). Nonetheless, Loewen (2004) stated that successful uptake, the learners’ immediate responses (of whatever type) to corrective feedback, is a fairly reliable indication of a learner’s perception of the mismatch between the target-like structure and his/her problematic utterance. Another point to be discussed is that learners should recognize the function and force of the corrective feedback. Carroll (2001) argued that it is essential for learners to recognize the source of their errors i.e., what kind of error they have made. Thus, examining whether learners produce the desirable modified output following recasts, particularly during mobile-mediated audio and video interactions, merits further attention. Hence, the aim of the present study is two-fold. The first goal is to investigate learners’ perceptions of recasts in mobile mediated settings including synchronous audio and video-based platforms compared to the face-to-face settings. The second aim of the present research is to examine learners’ modified output following mobile-mediated recasts during audio and video-based communication.
Literature Review
Mobile Assisted Language Learning
Mobile technology has substantially enabled learners to autonomously opt for their language learning progress (Reinders & Benson, 2017), engaging them in a different style of learning and leading to the advent of mobile-assisted language learning (MALL) (Burston, 2015; Duman et al., 2015; Shadiev et al., 2017). A palpable superiority of MALL over the conventional classes can be the ubiquity it yields (Xu & Peng, 2017). That is, mobile technology offers the learners a new approach that is permanent, mutual, accessible and affordable. In other words, the utility and significance of MALL reside in the continuity or spontaneity of access and interaction across its different contexts of use (Chinnery, 2006; Kukulska-Hulme & Shield, 2008; Traxler, 2007). Recently, new developments in Web 2.0 such as instant messaging tools and social media applications have provided excellent opportunities for language learners to interact with each other through online communication.
Corrective Feedback, Modified Output and Uptake
Sheen (2007) defined CF as a reactive move, performed by the teacher, calling a learner’s attention to notice his/her erroneous utterance. CF is generally considered implicit or explicit depending on how obtrusive it is to the flow of communication; the more obtrusive the feedback, the more explicit it would be to the learner (Brown, 2007). CF is typically divided into six patterns: explicit correction, recasts, metalinguistic feedback, elicitation, repetition, and clarification request (Lyster & Ranta, 1997). As a kind of CF and a reactive move represented by the instructor, recasts assist L2 development by helping learners identify the mismatch between their incorrect and the target-like utterance. A recast is assumed to implicitly render assistance to learners in raising their consciousness to perform cognitive comparisons so as to discern erroneous utterances and find the correct target form while a focus on meaning is still preserved (Ellis, 1994; Sheen, 2007). Such an interpretation has been also acknowledged in Long and Robinson’s (1998) dichotomy of feedback types where recasts are introduced as meaningful implicit focus-on-form techniques. Recasts are also welcome in a language classroom because they are time-saving and non-interruptive for the flow of communication. Yet, the saliency of recasts might be criticized due to their ambiguity in pinpointing errors involved in learners’ utterances (Lyster, 1998). Accordingly, the effectiveness of recasts hinges on their saliency and the extent to which they are detected and correctly interpreted by learners.
There are four different ways to measure the efficacy of CF in language classrooms such as examining learners’ uptake, post-testing in experimental designs, and measuring learners’ perception or noticing of CF via stimulated recall interviews (e.g., Han, 2002; Long & Robinson, 1998; Lyster & Ranta, 1997; Mackey et al., 2000). Uptake is referred to as the learner’s immediate response to CF provided by the teacher. As explained by Lyster and Ranta (1997), uptake refers to “a student’s utterance that immediately follows the teacher’s feedback and constitutes a reaction in some way to the teacher’s intention to draw attention to some aspect of the student’s initial utterance” (p.49). When learners receive CF in response to their linguistic production, their uptake can be categorized in either of the following two categories: (1) they might perceive it and, as a response, produce a correct or partly correct reformulation, i.e., modified output, of their former error that exhibits at least some understanding of the teacher’s corrective endeavor or (2) they might reproduce their ill-formed utterance that shows no sign of amelioration in the learning process and the learner may still be required to receive further correction, i.e., non-modified output (Lyster and Ranta, 1997). In the latter, learners might repeat the error with no correction at all or utter a simple acknowledgment of the teacher’s correction such as Yeah, Ok, etc. Therefore, by providing CF, teachers may not expect that their CF would definitely be conducive to learners’ error-free production. According to Lyster and Ranta (1997), as a learner’s modified output corresponds to the correct target-like form, it is termed as a “repair”. On the contrary, if the learner’s modified output is still incorrect, it is called “needs repair”. Consequently, it should be noted that modified output is one of the various types of uptake; however, not all uptakes necessarily take the form of a modified output.
Some studies indicated associations between learners’ uptake and their perceptions and noticing of CF (e.g., Egi, 2010; Kim & Han, 2007). Kim and Han (2007), for instance, reported that learners’ perceptions depended on the linguistic target of the recasts and they were able to identify their teachers’ intents with simple recasts than with the complex ones. Moreover, Egi (2010) investigated the relationship between learners’ perception of recasts, their uptakes, and their modified output among 24 Japanese EFL learners. Learners who participated in the study received CF from their interlocutors while performing some task-based activities. The findings revealed that there was a meaningful relationship between the learners’ response to the recasts and their increasing potential to grasp the interlanguage-L2 discrepancies. In addition, both learners’ recognition of corrective moves and their noticing the gap were reported to be significantly associated with modified output. As the ultimate goal of CF is to promote and enhance L2 development, the uptake is required to induce a modification endeavor that prompts amelioration in at least one facet of linguistic production (e.g., grammar, vocabulary, etc.) (Mackey & Philp, 1998).
Technology Mediated Corrective Feedback
Due to the advancement of technology, some studies have focused on examining the efficacy of CF delivered during computer-mediated interactions. For instance, Yilmaz (2012) investigated the effectiveness of recasts and explicit corrections in the text-based computer-mediated and face-to-face communication while emphasizing the two target structures. The findings revealed that devoid of accounting for the modes of communication, both explicit and recast CFs were efficacious, whereas the explicit one was slightly more compelling.
A number of studies investigated the effects of CF in Computer Assisted Language Learning (CALL) (e.g., Jiang & Eslami, 2021; Sachs & Suh, 2007; Shintani, 2016; Shirani, 2020; Yamashita 2020; Yilmaz, 2012; Yilmaz & Yuksel, 2011). Yet, these studies have almost exclusively concentrated on CALL to evaluate the effectiveness of CF through text-based communication (e.g., Shintani, 2016; Yilmaz, 2012) and little attention has been paid to providing CF through online communication modes such as video- and audio-based (Rassaei, 2019). Although the number of studies dealing with CF and CALL is substantial, few studies have focused on the use of MALL and CF. (e.g., Chang & Hsu, 2011; Smith & Wang, 2013). One exception is Xu and Peng’s (2017) research, where they investigated the contribution of mobile-mediated oral feedback among 13 learners of Chinese as a second language. The results indicated that the learners enjoyed positive impressions on mobile-mediated CF and they purported that such an approach facilitated their learning and enhanced their communicative capability. Besides, Xu, Don, X, & Jiang (2016) investigated Chinese EFL learners’ perceptions of mobile-mediated oral feedback utilizing WeChat mobile application. They indicated the facilitative contribution of WeChat feedback to promoting the learners’ speaking abilities. Pourdana, Nour, & Yousefi (2021) examined the contradictory role of written corrective feedback on discourse markers in an online mobile mediated setting. They did not find any significant long-term improvement in the accuracy of discourse markers after receiving metalinguistic corrective feedback online.
In short, based on the research gap in terms of implementing CF through MALL, the current study follows two objectives. The first objective is to investigate the learners’ perceptions of recasts through mobile-delivered interactions including audio- and video-based platforms. The video- and audio-based communication incorporated in this study comprises the synchronous dyadic transmission of video images and audio communication through WhatsApp and excludes text messaging. The second objective of the present study is to investigate the learners’ modified output in response to recasts during audio-based and video-based communication. To this end, the following research questions were responded in this study.
- Is there any significant difference in learners’ modified output (i.e., uptake) in response to recasts during mobile-mediated video and audio interactions?
- Is there any significant difference in learners’ perceptions of recasts provided during mobile-mediated audio and video interactions compared to the face-to-face communication?
Method
Design
The design of the present study can be considered as a descriptive quantitative one in which the researchers try to investigate learners’ perceptions and modified output in response to recasts in three conditions: face-to-face, video-based and audio-based.
Participants
The primary participants included 83 intermediate Iranian EFL students at the B2 level chosen from 2 language schools, 60 of whom completed the consent forms. Intermediate EFL learners(B2) were chosen because they were fluent enough to narrate a story, though not accurate enough to do so without errors. Little (2011), asserts that intermediate learners are able to interact easily and spontaneously yet, they don’t have a great command of the English language to speak without errors. They were chosen from a large population of intermediate learners via cluster sampling and their proficiency level was checked through Oxford Placement Test. Accordingly, three groups were assigned: face-to-face (n= 20), audio-based, (n= 20), and video-based (n=20) feedback groups. Of this number, 20 were females and 40 were males. Their age range was between 18 to 30. It is noteworthy that the English proficiency level of students was considered in this study, not their gender or age.
Materials
Three short stories were chosen from www.shortstories.net. These stories included Little Red Riding Hood, Peter and the Wolf, and The pied-piper of Hamelin. The storytelling task was chosen because it is asserted to be among the facilitative tasks that are beneficial in stimulating students’ learning outcomes and promoting L2 learning (Muranoi, 2007). The passages were the same for the three groups. The difficulty level of the three passages was at the intermediate level. The word count of the stories indicated 170, 240, and 300, respectively.
Target structure
The primacy of the content Word Principle (VanPatten, 2004) proposed that learners, while processing input, are inclined to process content words prior to function words due to the restricted capacity of memory. Thus, the aspects of English that may be non-salient to the learners are needed to be crucially taken into account (Sheen, 2008). Accordingly, the focus of the analysis in the present study was on the English definite article ‘the’ and the indefinite article ‘a’ as two function words which, based on some observations, the learners mostly experienced some problems with while they were provided with CF. In addition, the indefinite article ‘a’ refers to someone or something for the first time, and the definite article ‘the’ refers to someone or something mentioned before. In a meaning-based communicative task, the elicitations of such structures are moderately simpler than the other aspects of grammar. Moreover, articles are reflected differently in English and Persian. In Persian, these articles, carrying the same concept, appear as suffixes that are attached to the end of nouns while in English they are presented before nouns. Due to such differences, Persian EFL learners normally tend to have difficulties with the accurate use of English articles.
Data Collection
For the face-to-face group, the three different short stories were provided in three different sessions. It should be noted that the present study did not include treatment sessions and these three sessions were intended to collect learners’ perceptions of corrective feedback. Each session was scheduled so that all learners were present in class with the researcher. Each session, the students were provided with one short story and they were asked to read the short stories for ten minutes. In the next step, the stories were collected by the researcher, and the students were asked to orally reproduce the stories in their own words. At the reproduction time, the students were required to stay outside the classroom and came in one by one to have their CF sessions with their teachers. Thus, during each dyad, only the student and the teacher were present in the classroom. This process was performed to reduce the level of stress and enhance the focus of the learners on the task itself. The students were free to ask the meaning of unknown words before the storytelling task was started. During their interaction, the students received recasts in line with their errors. Each of these dyads lasted for approximately 10 minutes. All the interactions between the researcher and students were audio-taped for further analysis. In terms of the content, the video-based recasts sessions were exactly the same as the face-to-face ones.
However, in terms of modality, first, the researcher video-called each student via WhatsApp through their cell phones and sent them one of the short stories. A 10-minute period was allotted to each learner to study the story. Afterwards, the researcher asked the learner to orally reproduce the story via video chat. The learners were already familiar with making video calls through WhatsApp. Similar to the face-to-face mode, the learners were free to ask the meaning of unknown words. During the video chat, the learners’ erroneous forms were corrected by the teachers’ recasts. Each dyadic interaction was recorded for later analysis as well as for stimulated recall interviews. In terms of the content and procedure, the audio-based recasts sessions were exactly the same as the video-based ones. However, in terms of modality, the dyadic communication between the researcher and the learner was conducted via WhatsApp audio call on each learner’s cellphone. These audio calls were recorded via an audio recorder for later analysis.
Afterwards, a stimulated recall methodology was applied to gather data on the learners’ perceptions of recasts in the face-to-face, audio- and video-based groups. According to Gass and Mackey (2000), stimulated recall is an effective means to infer the learner’s noticing of feedback during dyadic interaction. To this end, the audio-recorded file of each dyadic interaction of the face-to-face group was appraised for detecting the corrective feedback episodes. The corrective feedback episodes encompassed those learner-teacher interactions which contained an erroneous form followed by a teacher’s provision of corrective feedback congruent with that error. Altogether, 215 feedback episodes were recognized for the face-to-face group. The feedback episode of each interaction was replayed to each learner. Then, the learners were required to retrospectively describe what he/she was thinking at the time of receiving feedback. To make the aim of the recall less apparent to the learners, several non-feedback episodes were integrated into the stimulated recall interviews. The learners were provided with intelligible instructions on how to think retrospectively considering the time of classroom interactions. They were free to pause the audio feedback episode several times at any point of the episodes to provide an apt description of their thought. The stimulated recall sessions were performed in the learners’ L1, Persian, to optimally facilitate the learners’ task. The participants were permitted to replay the audio-taped sessions per their request. The stimulated recall sessions were all audio-taped for subsequent analysis. Also, for the audio-based group, 190 feedback episodes were collected; then, the feedback episodes were played for each learner. After that, the learners were instructed to recall and report what they actually thought during or after each episode. Finally, for the video-based group, 132 episodes were collected and the same procedure was followed for this group as well. In order to accomplish the goals of the study, the teacher reformulated the learner’s erroneous sentence that involved an error in the L2 structure, i.e., full recasts. In other words, the recasts were full since the interlocutor corrected the complete sentence that involved the error then repeated it as in the following example:
- Learner: one day the little girl saw wolf.
- Interlocutor: one day the little girl saw a wolf.
Data Analysis
There were two types of analyses conducted in this study. First, the learners’ uptake and modified output in line with the recasts they received in the three groups, i.e., face-to-face, audio- and video-based were analyzed. Second, stimulated recall methodology was utilized to gather the data on the learners’ perceptions of the recasts. In order to achieve the first objective of the study, the learner’s reformulated uptakes, i.e., modified outputs, were coded in terms of their accuracy and the extent to which they corresponded with the correct target-like form. Accordingly, three types of modified output were identified: (1) Uptake without modified output, (2) Non-target-like modified output, and (3) Repair. Uptake without modified output was defined as when learners showed a verbal reaction to the recast but it was not clear whether the learners understood the interlocutor’s recasts as corrective feedback or not, as in the following example:
- Learner: The mayor accepted offer.
- Interlocutor: The mayor accepted the offer.
- Learner: Okay, yes …
Non-target-like modified output was the time when learners perceived the recast to some extent and attempted to reproduce the correct structure though he/she could not. This is exemplified in the following sample:
- Learner: Some of a neighbors didn’t pay attention to peter this time and …
- Interlocutor: Some of the neighbors didn’t pay attention to peter this time and …
- Learner: Some of neighbors didn’t pay attention to peter this time and …
Finally, the learners’ modified outputs were coded as repair when they identified and verbalized the source of the error while reformulating the corrected structure as in the following exemplar:
- Learner: Wood cutter cut the wolf’s stomach
- Interlocutor: The wood cutter cut the wolf’s stomach
- Learner: oh, excuse me, the wood cutter cut the wolf’s stomach
A total of 537 recast episodes were collected for the analysis pertaining to the learners’ modified output proceeded with recasts. Out of the total, 215 episodes belonging to the face-to-face group, 132 episodes pertained to the video-based group, and 190 episodes were associated with the audio-based group. According to the stimulated recall methodology, the learner’s extent of uptakes in line with respective corrective feedback was coded in terms of the accuracy of learners’ comments following the recasts. Based on Egi (2010), the learners’ stimulated recall comments were classified into three categories of noticed, recognized as corrective, and non-corrective. They were classified as noticed when learners were able to identify the source of the error as well as the discrepancy between their utterance and the target-like structure. The comments were classified as recognized as corrective whenever the learners acknowledged making a mistake, but failed to identify the source of the error. Finally, the learners’ comments were arranged as non-corrective when they failed to identify the corrective intent of the feedback. The following examples indicate how the learners’ stimulated recalls were classified based on these categories.
- Noticed
Learner: Oh here, I was wrong. It was correct to say “The neighbors found Peter laughing at them” but I said “Neighbors found Peter laughing at them” and he corrected my sentence.
- Recognized as corrective feedback
Learner: When I said “While she chose short path”, he corrected me.
Interlocutor: Did you understand what part of your sentence was wrong?
Learner: Um… actually I couldn’t find the mistake.
- Non-corrective
Learner: He repeated my sentence two times.
Interlocutor: Do you know why he repeated your sentence?
Learner: Not really.
A total of 537 corrective feedback episodes were coded for the stimulated recall analysis. Out of this number, 215 belonged to the traditional face-to-face group, 132 referred to the video-based group, and 190 pertained to the audio-based group. To account for inter-rater consistency, a second coder, who was trained on how to code data, was granted a random subset of the stimulated recall data (40%). Subsequently, the rater processed the identical data independently and coded them in terms of the mutually putative criteria. After the two coders assigned the reformulations to their corresponding categories, the results of their coding were almost in complete agreement and the inter-rater dependability was 90%. Since the type of data was categorical, the raw frequencies relevant to the three categories of the learners’ reformulations in reference to the provided recasts were submitted to Pearson’s Chi-square analysis.
Result
Table 1 illustrates the descriptive statistics pertaining to the frequency of the learners’ modified output in the three CF sessions. According to the table, among the three interaction modes, the learners in the audio-based group repaired 82.10% of their inaccurate utterances whereas in the video-based group 80.30% were repaired, and in the face-to-face group 80.28% of the responses were regarded as the repair. This issue elucidates that the learners in the audio-based group were slightly more capable of correcting their erroneous structures through recasts. Moreover, regarding responses in all of the three groups, the majority of the leaners’ production tended to be repaired since 81.12% of the entire responses were corrected by the learners, 11.66% of them were non-target-like modified output, and 7.22% were regarded as uptake without modified output. In other words, the repair was the most frequent response; uptake without modified output was the least frequent response in all of the three interaction modes. Table 1 also illustrates some discrepancies in the responses of face-to-face, audio-based and video-based groups. It appears that, among the three groups, the learners in the audio-based condition conveyed the highest rate of modified output in terms of recasts as the frequency of repair is higher (82.10%) in such a context.
Table 1. Descriptive Statistics of Learners’ Output
| Modality | Uptake without modified output | Non-target-like modified output | Repair | Total |
| Audio | 13: 6.85% | 21: 11.05% | 156: 82.10% | 190 |
| Video | 9: 6.83% | 17: 12.87% | 106: 80.30% | 132 |
| Face to Face | 18: 8.36% | 25: 11.36% | 172: 80.28% | 215 |
| Total | 40: 7.22% | 63: 11.66% | 434: 81.12% | 537 |
In addition, the frequency of the learners’ classified reformulations (responses) in line with the recasts, illustrated in Table 1, was submitted to Pearson’s Chi-square to examine whether there is a difference among the three modalities in terms of the rate of the participants’ modified output in each mode. As Table 2 indicates, the Chi-square analysis revealed that the differences among the three groups regarding their modified output were not statistically significant, χ2 (4, 536) = .739, p = .946, Cramer’s V= .026, providing evidence of an extremely weak association between learners’ modified output and their modes of interaction. In other words, these results indicate that the learners provided similar responses to recasts in the three interaction modes. Figure 1 provides a visual representation of learners’ modified output in reference to the recast among the three groups.
Table 2. Comparison of Learners’ Output
| Value | df | Asymp. Sig. (2-sided) | |
| Pearson Chi-Square | .739 | 4 | .946 |
| Cramer’s V | .026 | ||
| N of Valid Cases | 537 |
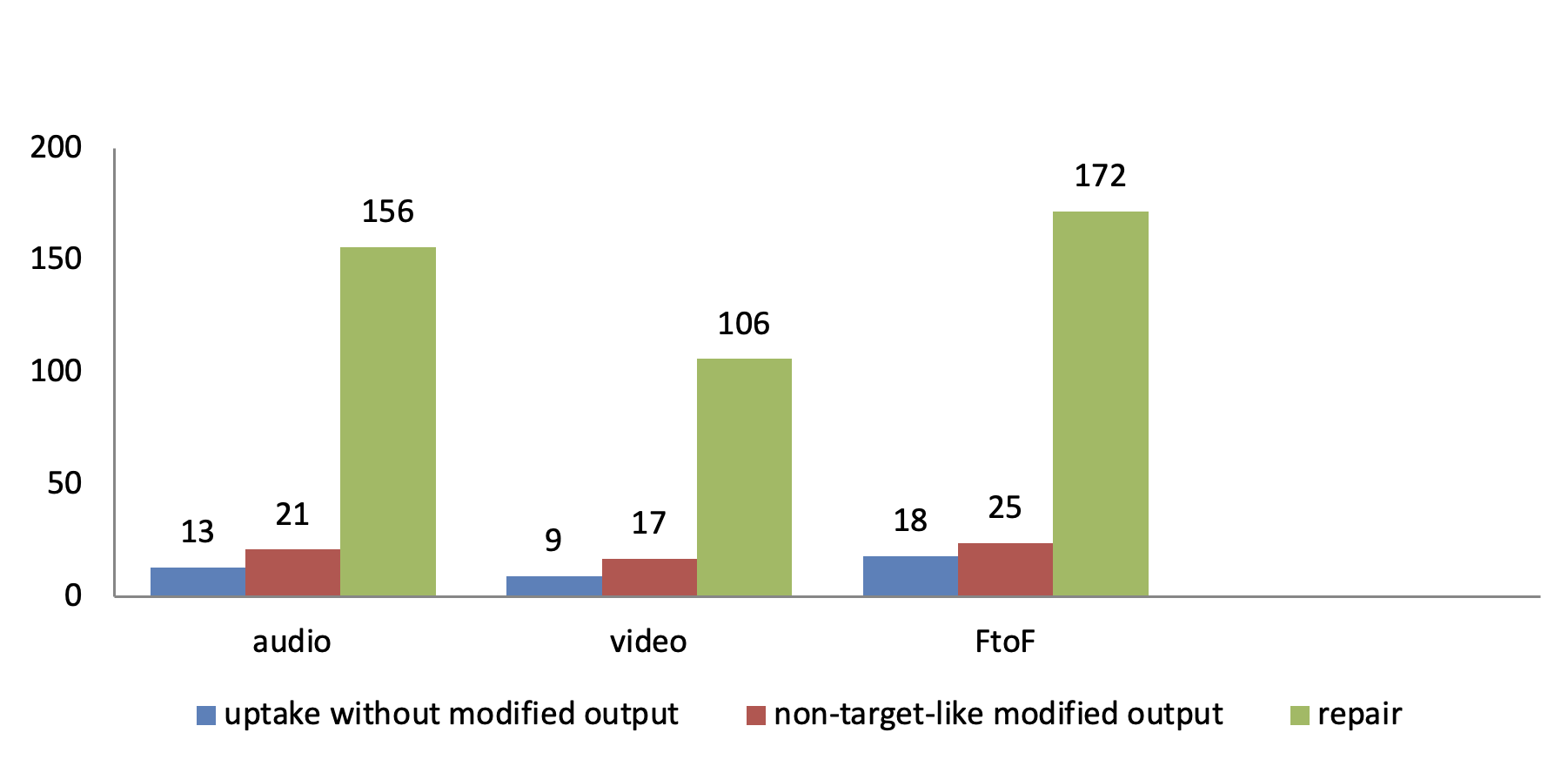
Figure 1. Learners’ output in audio-, video-based and face-to-face modalities
To investigate the statistical divergence among the learners of audio-based, video-based and face-to-face groups in terms of their perceptions of recasts, the frequencies of the learners’ perceptions of recasts were submitted to Pearson’s chi-square analysis (Table 4). The Chi-square analysis indicated a statistically significant difference (χ2 (4, 536) = 12.7, p = .013) regarding the learner’s perceptions of recasts among the three groups. Cramer’s V= .11 revealed a small association between the learners’ perceptions and the three modalities. Figure 2 displays the frequency of the three categories in terms of recasts noticing, i.e., (1) noticed (2) perceived as CF (3) perceived as non-CF among these three groups. Table 3 summarizes the learners’ perceptions of recasts through mobile-mediated audio and video interactions compared to face-to-face during the stimulated recall interviews. The learners in the audio-based group discerned 41.48% of the recasts, yielded 47.89% as corrective and 10.63% as non-corrective feedback. Moreover, the participants in the video-based group set forth 30.30% of their perceptions as noticed, 54.55 % as corrective feedback, and 15.15 % as non-corrective feedback. Ultimately, the face-to-face group signified 28.38 % of the recasts as noticed, 67.79 % as corrective feedback, and 8.83 % as non-corrective one. Accordingly, with respect to noticing the recasts, the learners in the audio-based group outperformed the other two groups since out of 190 episodes of recasts, 78 were perceived by this group; meanwhile, the lowest number of noticing appertained to the video-based group.
Table 3. Descriptive Statistics of Learners’ perceptions
| Modality | Noticed | Perceived as CF | Perceived as non-CF | Total |
| Audio | 78: 41.48% | 92: 47.89% | 20: 10.63% | 190 |
| Video | 40: 30.30% | 72: 54.55% | 20: 15.15% | 132 |
| Face to Face | 61: 28.38% | 135: 62.79% | 19: 8.83% | 215 |
| Total | 179: 28.45% | 299: 51.45% | 59: 20.10% | 537 |
Table 4. The Comparison of Learners’ perceptions
| Value | df | Asymp. Sig. (2-sided) | |
| Pearson Chi-Square | 12.727 | 4 | .013 |
| Cramer’s V | 0.11 | ||
| N of Valid Cases | 537 |
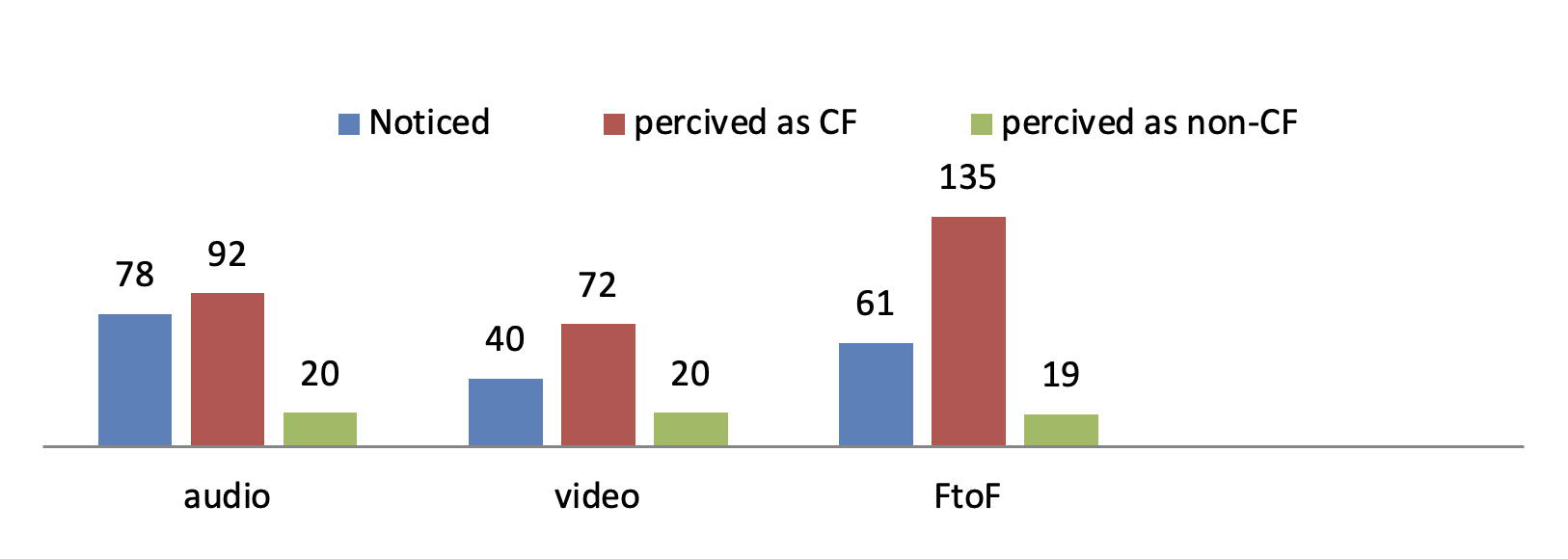
Figure 2. Learners’ perception of audio-based, video-based and face-to-face recasts
Discussion
Since this research sought to find answers to two questions, the results may be viewed from two dimensions. Firstly, the aim of the present study was to find whether there is any significant difference in terms of the learners’ uptake through audio- and video-based mobile-mediated recasts compared to face-to-face interaction. In this respect, the results elucidated that in comparison to the other two interaction modes, the learners in the audio-based condition had a slightly higher rate of modified output in response to the respective recasts as the frequency of repair was higher in this context. Consequently, this finding illuminated that the learners in the audio-based group were likely to apply more accurate structures vis-a-vis the received recasts. Moreover, in all of the three groups, the repair had the highest frequency; in contrast, uptake without modified output had the lowest frequency. Furthermore, the Chi-square analysis of the learners’ reformulations (responses) to the recasts in the three groups indicated no statistically significant differences in terms of their modified output (p= .946). Therefore, the answer to the first research question is negative; that is, mobile-mediated recast via video and audio as well as face-to-face communications can be regarded as equally effective for promoting L2 knowledge. The current findings in the domain of CF and MALL can be congruent with prior investigations in the literature (e.g., Loewen, 2004; Loewen & Philp, 2006; Sheen, 2004). In addition, the merits of MALL on the promotion of modified output can be corroborated by former research (Rassaei, 2019; Xu & Peng, 2017). It is worth noting that the operationalization of recasts via MALL and the promising results they yielded in terms of L2 development might be attributable and interrelated.
Secondly, in response to the second research question, the learners’ perceptions of recasts in the three input conditions were also investigated. The findings revealed that there was a significant difference among the learners’ uptakes in the three groups. This issue shows a strong consistency with the findings of prior research approving the positive contribution of recasts submitted through face-to-face instructional modes (e.g., Lyster & Izquierdo, 2009) as well as computer-mediated contexts (Sagarra, 2007; Yilmaz & Yuskel, 2011). Particularly, the current findings were rigorously in agreement with Rassaei’s (2019), confirming the higher noticeability of audio-based recasts to the learners in mobile-mediated communication. A reasonable justification for this issue might be germane to the optimal recasts uptake generated through the dyadic nature of audio-based interactions. This contention could be interpreted in the light of Schmidt’s (1990) noticing hypothesis. On the other hand, the learners in the audio-based group tended to notice the teacher’s recasts more rigorously since, in this mode, the teacher’s image was not a part of the recasts condition and the interactions were, in essence, less face-threatening than the video-based ones; consequently, the learners could apprehend and attend to the recasts and its corrective nature as well as their own erroneous structures with more fastidious care.
Correspondingly, some researchers (e.g., Mackey, 2006) have maintained that there is a link between noticed CF and L2 enhancement. Besides, there might be several other factors that could explain the efficacy of certain types of CF. For instance, Gass and Lewis (2007) stated that some learners who had an experience of learning a heritage language might be more prepared for the perception of CF they receive in learning a foreign language. Another factor that might be attributable to the efficacy of recasts is the linguistic context where the recast is provided. In other words, as a recast is detached from the original interaction, it might be less effective than a recast generated within the meaningful interactional context (Carpenter et al, 2006). In this vein, the present study also delineated that in addition to the aforementioned determinants, the input channel, serving recasts, might be a decisive constituent in facilitating the learners’ discernment of recasts and their corrective intent.
To recapitulate, the two crucial findings of the present study were as follows: (1) in mobile-mediated interaction, the audio-based recasts were more conducive to an optimal uptake inducing a correct reformulation compared to the recasts delivered during the conventional face-to-face communication. One plausible justification for this finding could be the potential of audio-based communication to reduce the learners’ stress levels and to provide them with additional processing time to contemplate the correct reformulation. Moreover, the positive effect that WhatsApp interaction brings about could be taken into account as an efficacious tool for distant education in Iran; (2) the accuracy of learners’ interpretations of recasts differed significantly in the three instructional settings. The audio-based group revealed an inclination towards gaining a more comprehensive impression of recasts compared to the other two groups. Accordingly, the recasts provided through the audio-based modality during the mobile-mediated communication appeared to prompt more noticing potential and less stress due to the absence of the teacher’s face-threatening issues; hence, this type of recast can be speculated to generate a more constructive impact on learners’ L2 development.
Conclusion Implications and Limitations
This exploratory research incorporated MALL into CF research to investigate the Iranian EFL learners’ modified output and their perceptions of recasts during synchronous video- and audio-based mobile-mediated dyadic interactions. The results indicated that the learners of the audio-based group had more accurate perceptions to recasts. At the same time, the results indicated no statistical significance of learners’ modified output in response to recasts among the three groups.
One implication of the current study is that synchronous audio-based instruction should be practical in distance education because it might create a less threatening environment for learners. The results of the present study are particularly significant at present due to the priority currently associated with distance education and social distancing as a consequence of the current pandemic. Although this study was conducted before the pandemic, the results could be applicable during the pandemic and even after that. These days, due to the difficult situation imposed by Covid-19, the requirements of social distancing are more consequential for educators as well as students. Since providing CF face-to-face or online plays a pivotal role in any learning process, the findings of this study emphasize the incorporation of technology-based platforms such as smartphones in promoting L2 development. Furthermore, the findings of the present study could highlight the essential role of blended learning which integrates online and face-to-face instruction in a post-pandemic era. In the present decade, the use of technology-based instruction and learning via smartphones is accelerated and different L2 learning programs are finding more up-to-date approaches to incorporate distant learning into their curriculum. Particularly, employing a mobile-mediated mode of interaction and the role it plays in providing CFs to learners’ errors might lead to promising results in the domain of L2 development.
Having presented the implication of the current study, however, limitations can be present in any study and this one is no exception. As Kim and Han (2007) mentioned, noticing is an ongoing process and learners’ memory of CF sessions is a product of their previous experience which might not be vividly remembered in subsequent stimulated recall interviews. Moreover, many of learners’ internal factors including working memory, anxiety, individual differences, and even their L1 might restrict their apt interpretation of teachers’ CFs. For these reasons, when interpreting the findings of the present study regarding stimulated recall interviews caution should be exercised. Future studies focusing on CF and mobile-mediated learning can include a larger sample size with more demographic divisions such as age, gender, location. Furthermore, other studies could replicate the study by aiming at inspecting mobile-based instruction and audio-based and video-based recasts with a shifted focus on other target structures like verb tense and subject-verb agreement. Despite the limitations of the current study, however, the results provide evidence that synchronous audio and video-based mobile interaction as modes of language interaction can facilitate learner development in and out of the classroom.
About the Authors
Javad Behesht Aeen is a Ph.D candidate in TEFL at Shiraz Azad University, Iran. He is an experienced EFL instructor whose areas of interests include language teaching, language assessment and language skills.
Ehsan Rassaei is Associate Professor of Applied Linguistics at Majan University College, Oman. His areas of interest include corrective feedback, technology-mediated instruction and dynamic assessment.
Mohammad Javad Riasati is a faculty member of Shiraz Azad University, Iran. He holds a PhD degree in Teaching English as a Second Language. His areas of interest include language teaching skills, language assessment, and individual differences.
Mostafa Zamanian is Assistant Professor of applied linguistics at Shiraz Azad University, Iran. He holds a PhD degree in Teaching English as a Second Language. His research areas include language teaching skills and curriculum development.
To cite this article
Aeen, J. B., Rassaei, E., Riasati, M. J. & Zamanian, M. (2022). EFL learners’ modified output and their perceptions of recast during face-to-face, audio-based and video-based synchronous mobile-mediated communication. Teaching English as a Second Language Electronic Journal (TESL-EJ), 25(4). https://tesl-ej.org/pdf/ej100/a5.pdf
References
Boston, J. (2021). Engagement with language: The utility of an under-utilized research construct. Research on Language and Culture.46, 43-55.
Brown, D. B. (2007). Principles of language learning and teaching, 6th ed. New York: Pearson.
Burston, J. (2015) Twenty years of MALL project implementation: A meta-analysis of learnin outcomes. ReCALL, 27(1): 4–20. https://doi.org/10.1017/S0958344014000159
Carpenter, H., Jean, K., MacGregor, D., Mackey, A., 2006. Recasts and repetitions: learners’ interpretations of native speaker responses. Studies of Second Language Acquisition 28, 209-236. https://doi.org/10.1017/S0272263107070416
Carroll, S. E. (2001). Input and evidence: The raw material of second language acquisition. Amsterdam: J. Benjamins.
Chang, C. K., & Hsu, C. K. (2011). A mobile-assisted synchronously collaborative translation–annotation system for English as a foreign language (EFL) reading comprehension. Computer Assisted Language Learning, 24(2), 155–180. https://doi.org/10.1080/09588221.2010.536952
Chinnery, G. M. (2006) Emerging technologies: Going to the MALL: Mobile assisted language learning. Language Learning & Technology, 10(1): 9–16.
Desouky. E (2020). The effect of employing task complexity with recasts on improving grammar acquisition among EFL Egyptian learners. Journal of Scientific Research in Education 21, 473-514.
Duman, G., Orhon, G. & Gedik, N. (2015) Research trends in mobile assisted language learning from 2000 to 2012. ReCALL, 27(2): 197–216. https://doi.org/10.1017/S0958344014000287
Egi, T. (2010). Uptake, modified output, and learner perceptions of recasts: learner responses as language awareness. Modern Language Journal, 94, 1-21. https://doi.org/10.1111/j.1540-4781.2009.00980.x
Ellis, R. (1994). The study of second language acquisition. Oxford University Press.
Gass, S.M., & Lewis, K. (2007). Perceptions of interactional feedback: Differences between heritage language learners and non-heritage language learners. In A. Mackey (Ed.), Conversational interaction in second language acquisition: A series of empirical studies (pp. 79–99). Oxford University Press.
Gass, S.M., & Mackey, A. (2000). Second language acquisition research. Stimulated recall methodology in second language research. Lawrence Erlbaum Associates Publication.
Han, Z. (2002). A study of the impact of recasts on tense consistency in L2 output. TESOL Quarterly, 36, 543–572. https://doi.org/10.2307/3588240
Jiang, W., & Eslami, Z. R. (2021). Effects of computer-mediated collaborative writing on individual EFL writing performance. Computer Assisted Language Learning. https://doi.org/10.1080/09588221.2021.1893753
Kim, J., & Han, Z. (2007). Recasts in communicative EFL classes: Do teacher intent and learner interpretation overlap? In A. Mackey (Ed.), Conversational interaction in second language acquisition: A series of empirical studies (pp. 269–297). Oxford University Press.
Kourtali, N. E., & Révész, A. (2020). The roles of recasts, task complexity, and aptitude in child second language development. Language Learning, 70(1), 179-218. https://doi.org/10.1111/lang.12374
Kukulska-Hulme, A., & Shield, L. (2008). An overview of mobile assisted language learning: From content delivery to supported collaboration and interaction. ReCALL, 20(3): 271–289. https://doi.org/10.1017/S0958344008000335
Little, D. (2011). The common European framework of reference for languages: A research agenda. Language Teaching, 44(3), 381. https://doi.org/10.1017/S0261444811000097
Loewen, S. (2004). Uptake in incidental focus on form in meaning-focused ESL lessons. Language Learning, 54(1), 153-187. https://doi.org/10.1111/j.1467-9922.2004.00251.x
Loewen, S., & Philp, J. (2006). Recasts in the adult English L2 classroom: Characteristics, explicitness, and effectiveness. The Modern Language Journal, 90, 536-56. https://doi.org/10.1111/j.1540-4781.2006.00465.x
Long, M. (1996). The role of the linguistic environment in second language acquisition. In W. Ritchie and T. Bhatia (eds), Handbook of Second Language Acquisition. Academic Press, 413 – 468.
Long, M., & Robinson, P. (1998). Focus on form: Theory, research, and practice. In C. Doughty and J. Williams (eds.). Focus on form in classroom second language acquisition (pp.15-41). Cambridge University Press.
Lyster, R., & Ranta, L. (1997). Corrective feedback and learner uptake. Negotiation of form in communicative classrooms. Studies in Second Language Acquisition, 19, 37-66. https://doi.org/10.1017/S0272263197001034
Lyster, R. (1998). Negotiation of form, recasts and explicit correction in relation to error types and learner repair in immersion classrooms. Language Learning, 48, 183-218. https://doi.org/10.1111/1467-9922.00039
Lyster, R., & Izquierdo, J. (2009). Prompts versus recasts in dyadic interaction. Language Learning, 59(2), 453-498.
Lyster, R., & Saito, K. (2010). Oral feedback in classroom SLA; A meta-analysis. Studies in Second Language Acquisition, 32(2), 265-302. https://doi.org/10.1017/S0272263109990520
Mackey, A. (2006). Feedback, Noticing and Instructed Second Language Learning. Applied Linguistics,27(3), 405-430. https://doi.org/10.1093/applin/ami051
Mackey, A., & Gass, S., McDonough, K. (2000). How do learners perceive interactional feedback? Studies in Second Language Acquisition, 22, 471-497. https://doi.org/10.1017/S0272263100004010
Mackey, A., & Philp, J. (1998). Conversational interactional and second language development: Recasts, responses, and red herrings? The Modern Language Journal, 82(3), 338-56. https://doi.org/10.1111/j.1540-4781.1998.tb01211.x
Muranoi, H. (2007). Output practice in the L2 classroom. In R. DeKeyser (Ed.), Practice in a second language: Perspectives from applied linguistics and cognitive psychology. Cambridge University Press.
Nassaji, H. (2009). Effects of recasts and elicitations in dyadic interaction and the role of feedback explicitness. Language Learning, 59, 411–452. https://doi.org/10.1111/j.1467-9922.2009.00511.x
Pourdana, N., Nour, P., & Yousefi, F. (2021). Investigating metalinguistic written corrective feedback focused on EFL learners’ discourse markers accuracy in mobile-mediated context. Asian-Pacific Journal of Second and Foreign Language Education, 6(1), 1-18.
Rassaei, E. (2019): Recasts during mobile-mediated audio and video interactions: learners’ responses, their interpretation, and the development of English articles. Computer Assisted Language Learning. https://doi.org/10.1080/09588221.2019.1671461
Reinders, H. & Benson, P. (2017) Research agenda: Language learning beyond the classroom. Language Teaching, 50(4):561–578. https://doi.org/10.1017/S0261444817000192
Sachs, R., & Suh, B. R. (2007). Textually enhanced recasts, learner awareness, and L2 outcomes in synchronous computer-mediated interaction. In A. Mackey (Ed.), Conversational interaction in second language acquisition (pp. 197–227). Oxford University Press.
Sagarra, N. (2007). From CALL to face-to-face interaction: The effect of computer-delivered recasts and working memory on L2 development. In A. Mackey (Ed.), Conversational interaction in second language acquisition (pp. 229–248). Oxford University Press.
Shadiev, R., Hwang, W. Y. & Huang, Y.-M. (2017) Review of research on mobile language learning in authentic environments. Computer Assisted Language Learning, 30(3–4): 284–303. https://doi.org/10.1080/09588221.2017.1308383
Sheen, Y. (2004). Corrective feedback and learner uptake in communicative classrooms across instructional settings. Language teaching research, 8, 263–300. https://doi.org/10.1191%2F1362168804lr146oa
Sheen, Y. (2007). The effects of corrective feedback, language aptitude, and learner attitudes on the acquisition of English articles. In A. Mackey (Ed.), Conversational interaction in second language acquisition (pp. 301–322). Oxford University Press.
Sheen, Y. (2008). Recasts, language anxiety, modified output, and L2 learning. Language Learning, 58, 835–874. https://doi.org/10.1111/j.1467-9922.2008.00480.x
Sheen, Y. (2010). Differential effects of oral and written corrective feedback in the ES classroom. Studies in Second Language Acquisition, 31(2), 203-34. https://doi.org/10.1017/S0272263109990507
Shintani, N. (2016). The effects of computer-mediated synchronous and asynchronous direct corrective feedback on writing: a case study. Computer Assisted Language Learning, 29, 517–538. https://doi.org/10.1080/09588221.2014.993400
Shirani, R. (2020). Explicit versus implicit corrective feedback during videoconferencing: Effects on the accuracy and fluency of L2 speech. Unpublished PhD thesis, University of Victoria. Canada.
Schmidt, R. (1990). The role of consciousness in second language learning. Applied Linguistics, 11, 129-158.
Smith, S., & Wang, S. (2013). Reading and grammar learning through mobile phones. Language Learning & Technology, 17(3), 117–134. Retrieved from http://llt.msu.edu/issues/october2013/wangsmith.pdf
Swain, M. (2006). Languaging, agency and collaboration in advanced language proficiency. In H. Byrnes (Ed.), Advanced language learning: The contribution of Halliday and Vygotsky (pp. 95–108). Continuum.
Traxler, J. (2007) Defining, discussing and evaluating mobile learning: The moving finger writes. The International Review of Research in Open and Distance Learning, 8(2): 1–12.
VanPatten, B. (2004). Input processing in SLA. In B. VanPatten (Ed.), Processing instruction: Theory, research, and commentary (pp. 5–31). Erlbaum.
Xu, Q., Don, X. Q., & Jiang, L. (2016). EFL learners’ perceptions of mobile-assisted feedback on oral production. TESOL quarterly. https://www.jstor.org/stable/44984761
Xu, Q., & Peng, H. (2017): Investigating mobile-assisted oral feedback in teaching Chinese as a second language, Computer Assisted Language Learning, http://doi.org/10.1080/09588221.2017.1297836
Yamashita, T. (2021). Corrective feedback in computer mediated collaborative writing and revision contributions. Language Learning & Technology 25(2), 14-39.
Yilmaz, Y., & Yuksel, D. (2011). Effects of communication mode and salience on recasts: A first exposure study. Language Teaching Research, 15, 457–477.
Yilmaz, Y. (2012). The relative effects of explicit correction and recasts on two target structures via two communication modes. Language Learning, 62, 1134–1169. https://doi.org/10.1111/j.1467-9922.2012.00726.x
Appendix
First story: Peter and the Wolf
Once upon a time, there was a little shepherd who lived in a town near the woods. His name was Peter, and he always took care of his flock. He was often bored and alone on the field and he used to play alone and invented many games to entertain himself. One time he had an idea to have fun at the expense of his neighbors. One day, Peter started to shout- ‘Help, Help. The alarmed neighbors ran out to help him but they just found Peter laughing at them- Ha-ha, ha, you are so silly, I was joking’. The neighbors were angry and went back home. The next day, Peter did the same- ‘Help, help the wolf is coming. Some of the neighbors didn’t pay any attention, but others ran out again to help Peter. But again, it was just a bad joke. Peter couldn’t stop laughing and the good neighbors then decided to ignore him. The day after, Peter the shepherd was with his flock when a big wolf appeared and started to kill the sheep. Peter couldn’t believe it, and he shouted again- Help, help a wolf is eating my sheep. But no one in the town ran out to help him. The wolf ate all the sheep and Peter felt really destitute. From that day on, he never lied again and he had to look for a job as he didn’t have any sheep left to care for.
Second story: The pied piper of Hamelin
Once upon a time there was a little town called Hamelin, located among the mountains and surrounded by beautiful fields. One day, a lot of rats arrived in Hamelin. The rats ran around everywhere and so the terrified citizens went to plead with the town councilors to free them from this plague. The mayor was in his office trying to think of a plan, when a young man with a golden flute appeared, and offered to rid him and the town of rats in exchange for one million euros. “If you solve this problem I will pay you”- said the Mayor so, that night, a sound of a flute was heard throughout the streets of Hamelin. All the rats followed the pied piper as he marched down to the river and straight into the water behind him the swarm of rats followed him and every one of them was drowned and swept away by the current. Once back in town, the pied piper went to claim his payment- “did you really think that I was going to pay you one million Euros? Said the Mayor, – “I don’t have that amount of money and besides anyone can do what you did”. This made the pied piper really furious. He went out and started to play his golden flute again. Suddenly all the children started to follow him. Their parents were desperate because their children were running after the young man and the sound of his flute as if hypnotized. The pied piper of Hamelin took the children away and they were never seen again. The Mayor had learned his lesson and he never lied again, but he never found the children that had disappeared and so he had to shoulder the blame and suffer the consequences for the rest of his life.
Third story: Little Red Riding Hood
Once upon a time, there was a little girl called Little Red Riding Hood. One day, her mother said: “Little Red Riding Hood, take this basket full of cakes to your grandmother, she is ill. Don’t distract on the way, the forest is dangerous and there is a wolf around. “Yes Mum”- said Little Red Riding hood. Little Red Riding Hood walked happily to her grandmother’s house, but suddenly, a wolf appeared.
-where are you going Little Red Riding Hood?
-to my granny’s house, to give her these cakes.
The wolf convinced the girl to take a longer path while he took the short path, so he could arrive before her and eat her grandmother. Then he ate Little Red Riding Hood. Later, after eating them, the wolf fell asleep beside the river. Suddenly, a woodcutter saw him and took the little girl and her granny out of the wolf’s stomach and saved their lives. Then he filled the wolf’s belly full of big stones and threw him into the river.
| Copyright of articles rests with the authors. Please cite TESL-EJ appropriately. Editor’s Note: The HTML version contains no page numbers. Please use the PDF version of this article for citations. |